First Week at Notes on Reinforcement Learning
Introduction, plan, classification and notes on RL

Hi, my name is Francisco Rodríguez Cuenca, and I’m a Research Assistant on AI and an Assistant Professor on Probability and Statistics, at ICAI School of Engineering (Madrid, Spain).
I have created this Substack as a way to keep up with the world of Reinforcement Learning, and to practice the art of teaching it to others. Also, I’m hoping this process will help me to find the subject for my phd thesis.
Well… what’s the plan?
The plan is to update subscribers on the latest developments in Reinforcement Learning on a weekly basis. Since my interests are mainly human interaction, multi-agent applications and game theory, highlighted articles will probably lean that way.
Just to be clear, I am in no way an expert in Reinforcement Learning, just one AI researcher that needs a whole lot of researching to do before he feels confident complaining about imposter syndrome.
Also… feel free to destroy with constructive criticism anything you read here, everything can be made better and that’s kind of the plan too.
This week’s notes
This week’s research process has been the following:
Download all papers announced the previous week on arxiv.org
Read the abstracts and classify the papers in a totally arbitrary manner
Read the details of selected group of articles that I find interesting
Tell you everything about it
A total of 51 papers were announced from the 26th of December to the 2nd of January, I didn’t expect so many. Also, I’m guessing that sorting them by announcement date is not the best thing since some of them were a bit older.
Let me tell you about my totally arbitrary way of classifying them:
Engineering Applications (papers about using RL in a useful way)
Financial Applications (papers about using RL to make money)
Transformer Theory (RL + Transformers, what could go wrong)
NLP Applications (Natural Language Processing + RL, this really could go very wrong, nazi chatbots kind of wrong)
Mathematical Theory (these are papers that I either won’t ever understand slash will have to forget about ever having a family, a home, or any kind of fulfilling life to understand)
Reinforcement Learning Theory (I suppose half of these could go into Mathematical Theory but I kind of see what they are about, just enough to hope that one day I might understand them)
Game Theory (the interesting stuff)
Once I had read all the abstracts and taken some notes, I chose the best ones and read them using the first pass of Keshav’s three pass aproach.
Behold, the best ones
On the subject of Reinforcement Learning Theory we have…
Towards Learning Abstractions via Reinforcement Learning
More efficient inter-agent communication by interleaving RL with higher level abstractions.
Outcome-Driven Reinforcement Learning via Variational Inference
Inferring a reward function for goal-directed tasks instead of heuristically designing it.
Backward Curriculum Reinforcement Learning
Improving sample efficiency on simple tasks by training agents with the trajectories reversed and a strong reward signal.
And on Game Theory we have…
Warmth and Competence in Human-Agent Cooperation
Predicting users' preferences regarding to different agents on mixed-motive games can be improved with people's perceptions, either stated on warmth and competence metrics, or revealed by asking if they prefer to continue playing with that agent or to play alone.
Independent and Decentralized Learning in Markov Potential Games
Proof that RL agents can reach a stationary Nash equilibrium in Markov Potential Games through simple learning dynamics under a minimum information environment.
Classification of papers
Game Theory
Reinforcement Learning Theory
Improving generalization in reinforcement learning through forked agents
Strangeness-driven Exploration in Multi-Agent Reinforcement Learning
Representation Learning in Deep RL via Discrete Information Bottleneck
Risk-Sensitive Policy with Distributional Reinforcement Learning
Certifying Safety in Reinforcement Learning under Adversarial Perturbation Attacks
Bellman Meets Hawkes: Model-Based Reinforcement Learning via Temporal Point Processes
Outcome-Driven Reinforcement Learning via Variational Inference
Transformer Theory
Mathematical Theory
Offline Policy Optimization in RL with Variance Regularizaton
Learning Individual Policies in Large Multi-agent Systems through Local
Model-Based Reinforcement Learning with Multinomial Logistic Function Approximation
Revisiting the Linear-Programming Framework for Offline RL with General Function Approximation
On Pathologies in KL-Regularized Reinforcement Learning from Expert Demonstrations
Invariance to Quantile Selection in Distributional Continuous Control
Engineering Applications
Data-driven control of COVID-19 in buildings: a reinforcement-learning approach
Decentralized Voltage Control with Peer-to-peer Energy Trading in a Distribution Network
Driving in Dense Traffic with Model-Free Reinforcement Learning
RL and Fingerprinting to Select Moving Target Defense Mechanisms for Zero-day Attacks in IoT
Using Simulation Optimization to Improve Zero-shot Policy Transfer of Quadrotors
How to Train Your Gyro: Reinforcement Learning for Rotation Sensing with a Shaken Optical Lattice
On Deep Recurrent Reinforcement Learning for Active Visual Tracking of Space Noncooperative Objects
Finance Applications
NLP Applications
First pass on the interesting articles
Here is where I write notes on the papers I’ve more closely read using the first pass of Keshav’s three pass aproach. These are only notes I take as best as I can, so be prepared for them to be not useful/contain some errors. If you’d like anything to be done differently or spot some errors, comments are welcomed.
Towards learning abstractions via reinforcement learning
Erik Jergéus
Leo Karlsson Oinonen
Emil Carlsson
Moa Johansson
Chalmers University of Technology, Gothenburg, Sweden
AIC 2022, 8th International Workshop on Artificial Intelligence and Cognition
Keywords: Reinforcement Learning, Multi-Agent Systems, Neuro-symbolic systems, emergent communication
Jergéus, E., Oinonen, L. K., Carlsson, E., & Johansson, M. (2022). Towards Learning Abstractions via Reinforcement Learning. arXiv preprint arXiv:2212.13980.Abstract
New approach of synthesis of efficient communication schemes in multi-agent RL systems
Combine symbolic methods with machine learning - neurosymbolic
Reinforcement Learning is interleaved with steps to extend the current language with novel higher-level concepts, allowing generalization and more informative communication via shorter messages
This aproach allows agents to converge more quickly on a small construction task
Introduction
Learning to communicate and coordinate via interactions is often viewed as a prerequesite for developing artificial agents capable to do complex machine-to-machine and machine-to-human-communication
A striking characteristic that has been overlooked in the literature is the ability to derive concepts and abstractions from primitives, via interaction
Human Builder-architect experiments
The architect is given the drawing of a shape, and has to instruct the builder on how to construct it from samall blocks.
As the experiment progressed, participants developed more concise instructions (e. L-shape)

Study
Our constribution here is an initial feasability study of a neuro-symbolic multi-agent reinforecement learning framework for the builder-architect task
Inspired by neuro-symbolic program synthesis, the agent interleave reinforcement learning to train their neural network, with symbolic reflection to introduce new concepts for common action sequences
Agents learn to construct the given shapes faster when allowed the capability to introduce abstractions
Sections
Introduction
Implementation
The Environment
Seep Reinforcement Learning
Abstraction Phase
Experimental Results
Conclusion and Future Work.
Conclusion and Future work
Conclusion
Neuro-symbolic framework for learning liguistic abstractions via a combination of reinforcement learning, symbolic reasoning and interactions between agents.
Results suggest that it is feasible for reinforcement learning to develop useful abstractions by alternating between neural learning and symbolic abstraction
The introduced abstract concepts also greatly improve the performance of the agents.
Future work
Extend to more complex environments:
The agents might need to first develop several inmediate abstractions, before being useful. Solving this exploration-explotation dilemma seems like a fundamental problem.
Explore scenarios where agents do not share exactly the same understanding of a message and are required to reason in a recursive fashion.
Outcome Driven Reinforcement Learning via Variational Inference
Tim G.J Rudner - Oxford
Vitchyr H Pong - UC, Berkeley
Rowan McAllister - UC, Berkeley
Yarin Gal - Oxford
Sergey levine - Uc, Berkeley
35th Conference on Neural Information Processing Systems (NeurIPS 2021)
Rudner, T. G., Pong, V., McAllister, R., Gal, Y., & Levine, S. (2021). Outcome-driven reinforcement learning via variational inference. Advances in Neural Information Processing Systems, 34, 13045-13058.Abstract
Reinforcement Algorithms provide automated acquisition of optimal policies
Practical Application requires manually designing function that not only define the task, but also provide sufficient shaping to accomplish it.
This paper views the problem of RL as inferring policies that achieved desired outcomes, instead of maximizing reward.
They propose a a novel variational inference formulation that allows them to derive a well-shaped reward function that can be learn directly from environment interactions
From the corresponding variational objective:
They derive a new probabilistic Bellman backup operator
Use it to develop an off-policy algorithm to solve goal-directed tasks
Demonstrate that their method eliminates the need for hand-crafted reward functions, leads to effective goal-directed behaviours.
Introduction
Design of the Reward Function
Has a very big impact on the resulting policy
It's very heuristic, lacks theoretical grounding, can make effective learning difficult, can lead to reward mis-specification
Alternative
Instead of framing the problem as finding a policy that maximizes a heuristically-defined reward function
Express it as inferring a state-action trajectory that distribution conditioned on a desired future outcome
Builds off on probabilistic perspectives on RL and goal-directed RL
The paper derives:
A tractable variational objective
A temporal-difference algorithm that provides a shaping-like effect for effective learning
A reward function that captures the semantics of the underlying decision problem and facilitates effective learning
Outcome-Driven Actor-Critic - Resulting Algorithm
Ameniable to off-policy learning
Applicable to complex, high dimensial continuous control tasks over finite or infinite horizons.
The resulting variational algorithm can be interpreted as a shaping method, where each iteration learns a reward function that automatically provides dense rewards (Figure 1)
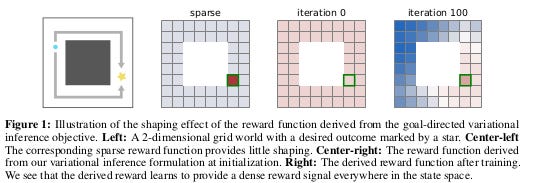
Works on tabular, non-tabular and deep learning approximation settings
Contributions
Probabilistic formulation of a general framework for inferring policies that lead to desired outcomes
Derivation of a variational objective from which we obtain a novel outcome-driven Bellman backup operator
Show that this Bellman backup operator induces a shaping-like effect and a clear and dense learning signal even in the first stages of training - this shaping emerges automatically from variational inference
Demonstrate that the resulting variational objective is lower-bound on the log-marginal likelihood of achieving the outcome given the initial state + leads to an off-policy temporal-difference learning algorithm.
We evaluate this algorithm - Outcome Driven Variational Inference (ODAC) -> results in significantly faster learng accross a variety of robot-manipulation and locomotion tasks.
Sections
Introduction
Preliminaries
Goal-conditioned Reinforcement Learning
Q-Learning
Outcome-Driven Reinforcement Learning
Warm-up: Achieving a Desired Outcome at a fixed time-step
Outcome-driven Reinforcement Learning as Variational Inference
Outcome-Driven Reinforcement Learning
Outcome-driven Policy Iteration
Outcome-driven Actor-critic
Related Work
Empirical Evaluation
Learning to achieve desired outcomes
Environments
Goal sampling
Baselines and prior work
Results
Ablation Study on the effect of a variational discount factor
Conclusion
Conclusion
ODAC - Outcome-Driven Actor Critic leads to efficient outcome-driven approaches to RL
It works well with simple dynamics models and suppose that also for more sophisticated ones: future area of research (epistemic uncertainty, domain specific structure)
Backward Curriculum Reinforcement Learning
Kyung Min Ko
Sajad Khodadanian
Siva Theja Maguluri
Georgia Tech
Ko, K., Khodadadian, S., & Maguluri, S. T. (2022). Backward Curriculum Reinforcement Learning. arXiv preprint arXiv:2212.1421Abstract
Current Reinforcement Learning:
Forward-generated trajectories to train the agent
Give the agent little guidance, so the agent can explore as much as possible
Trade-off = Losing sample efficiency
Novel Approach
Reverse Curriculum Reinforcement Learning
Starts training the agent using the backward trajectory of the episode rather than the forward trajectory
This gives the agent a strong reward signal, so the agent can learn in a more sample-efficient manner
Only requires a minor change in the algorithm -> Reversing the order of the trajectory before training the agent
Can be applied to any state-of-the-art algorithms
Introduction
Current Reinforcement Learning
Really sparse natural reward function since it is only given when the agent completes the task.
A lot of times the agent is blind to the task so it discovers optimal policy without any guidence from the human:
Large amount of computational power and samples to learn
Reverse Curriculum Reinforcement Learning
Uses trajectories in reverse order to train the agent
This enables our agent to start training by recognizing the goal of the task
Result: Agents are trained in an efficient way by utilizing strong reward signals during "reverse learning"
Does not need modification of neural structure nor new information, can be applied to any algorithm : PPO, A3C, SAC
2 simple steps:
Collect the trajectory of the agent as usual
Flip the order of the trajectory of the episode to train our agent
Curriculum Learning
Manually changes the order of the training process to train more efficiently
Tested
Tested on REINFORCE (Sutton) and REINFORCE with baseline
Cart-Pole V1 and Lunar-Lander_v2 - OpenAi Gym (Discrete Action Spaces)
Investigated the effects of return normalization technique, variation of learning rate and structure of neural network
Sections
Introduction
Related Works
Preliminaries
Reverse Curriculum Learning
Reverse Curriculum Learning in REINFORCE
Reverse Curriculum Learning in REINFORCE with baseline
Experimental Result
Cartpole Environment
Lunar Lander Environment
Return Normalization
Comparison between Deep and Shallow Networks
Conclusion
Acknowledgement
Conclusion
Does need fewer samples
Best fits while doing simple tasks like Cartpole with shallow networks
Future work: apply on state-of-the-art algorithms on different environments
Warmth and competence in human-agent cooperation
Kevin R. McKee - Deepmind
Xuechunzi Bai - Princeton
Susan T. Fiske - Princeton
Proc. of the 21st International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2022), P. Faliszewski, V. Mascardi, C. Pelachaud, M.E. Taylor (eds.), May 9–13, 2022, Online.
Kevin R. McKee, Xuechunzi Bai, and Susan T. Fiske. 2022. Warmth and Competence in Human-Agent Cooperation. In Proc. of the 21st International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2022), Online, May 9–13, 2022, IFAAMAS, 33 pages.
Abstract
AI agents trained with deep reinforcement learning are capable of communicating with humans
Studies primarly evaluate human compatibility through "objective" metrics such as task performance -> obscures variation in levels of trust and subjective preference.
Uses the game of Coins -> 2 player social dilemma
Measure the preferred agents by participants
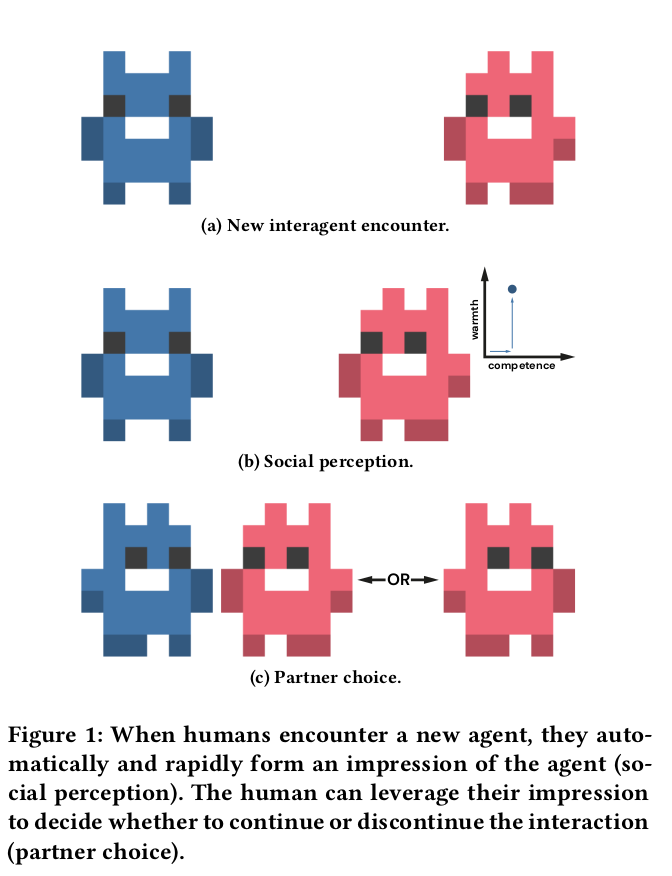
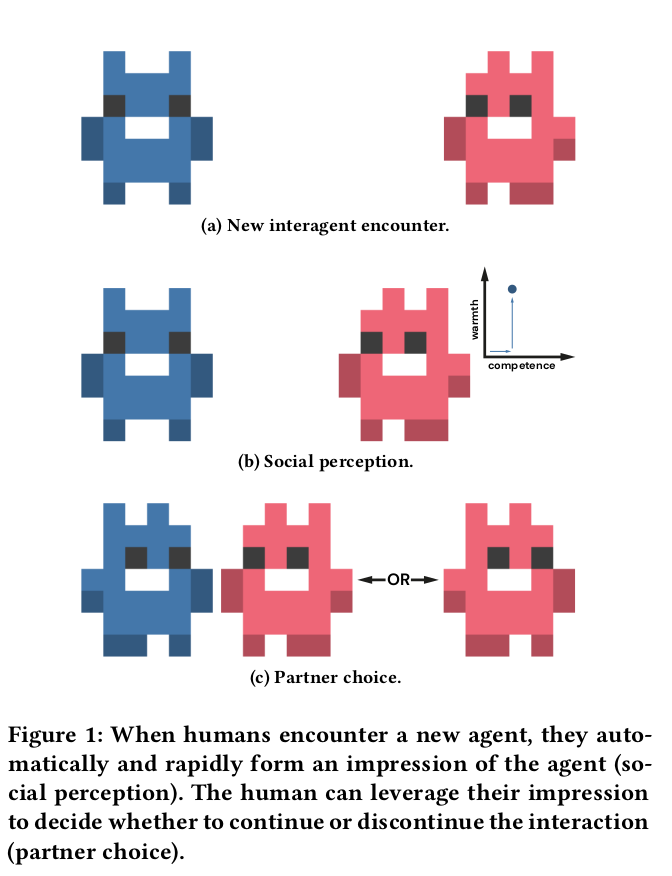
Perceptions of warmth and competence predict their stated preferences for different agents
Implementation of a new "partner choice" framework to elicit revealed preferences:
Participants play a round with an agent
Participants are asked if they want to continue with that agent or play alone
As with stated preferences, social perception better predicts participants' revealed preferences than does objective performance
Recommendation of the inclusion of social perception and subjective preference into studies
Love it!
Introduction
Contributions:
A. Demonstrates how reinforcement Learning can be used to train human-compatible agents for a temporal and spatially extended mixed-motive game
B. Measures both stated and revealed preferences, introducing a partner choice for the latter
C. Examines how fundamental social perceptions affect stated and revealed preferences over agents, above and beyond traditional objective metrics
Social perception:
Two underlying qualities:
Competence: Consistent with traditional ML scoring
Warmth: How aligned are this actor's goals and interests with one's own
Behavioural experiment:
Train RL agents to play Coins, a mixed-motive game, varying agent hyperparameters known to influence cooperation and performance
Three co-play experiments recruit human participants to interact with the agents:
measure participants' judgement of agent warmth and competence
elicit participant preference over the agents
Stated preferences:
Mostly used in experiments, often by directly asking participants
Insightful tools for research
Vulnerable to experimenter demand - Experimenter demand effects refer to changes in behavior by experimental subjects due to cues about what constitutes appropriate behavior.
Limited ecological validity
Eliciting revealed preferences:
Do people want to interact with the agent, if given the chance not to?
Well established revealed preference paradigm in evolutionary biology and behavioural economics
In incentivised experiments, parner-choice measures mitigate experimenters demand
In the context of algorithmic development, we can view partner choice as stand-in for the choice to adopt an AI system
Empowers participants with an ability to embrace or leave an interaction with an agent - and thus incorporate an ethic of autonomy into human-agent interaction research
Sections
Introduction
Methods
Task
Agent design and training
Study design for human-agent studies
Results
Agent training
Human-agent studies
Discussion
Discussion
This experiment demonstrates that artificial agents trained with DRL can cooperate and compete with humans in temporally and spatially extended mixed-motive games.
Prediction of preference
Agents elicited varying perceptions of warmth and competence
Predicting users' preferences can be done with objective features and improved with people's perceptions (stated or revealed)
Participants prefer warm agents over cold agents but, unexpectedly, also incompetent agents over competent agents
Mixed motive games
Mixed-motive games open new challenges related to motive alignment and explotability
Participants who played with (and exploited) altruistic agents expressed guilt and contrition. -> conflicts with research suggesting that humans are "keen to exploit benevolent AI"
Incentivised partner choices
Incentivised partner choices can help test whether new algorithms represent innovations people can be motivated to adopt
Close correspondance between stated and revealed preferrences -> stated preferences are still relevant (and cheap), can strenghen objective measures
Preferences are not a panacea
Does not solve the fundamental question of value alignment:
”How to ensure that AI systems are properly aligned with human values and how to guarantee that AI technology remains properly ameniable to human control" - Gabriel and GhazaviGabriel and Ghazavi identify shortcuts with both objective and subjective metrics
Independent and Decentralized Learning in Markov Potential Games
Chinmay Mheshwari - UC, Berkeley
Manxi Wu - Cornell University & UC, Berkeley
Druv Pai - UC, Berkeley
Shankar Sastry - UC, Berkeley
Maheshwari, C., Wu, M., Pai, D., & Sastry, S. (2022). Independent and Decentralized Learning in Markov Potential Games. arXiv preprint arXiv:2205.14590.Abstract
Multi-agent Reinforcement Learning Dynamics -> Analyze its convergence properties in infinite-horizon discounted Markov Potential Games
Focus on the independent and decentralized setting -> Players can only observe the realized state and their own reward on every stage
Players do not have knowledge of the game model and cannot coordinarte with each other
Learning Dynamics:
Players update their estimate of a perturbed Q-function that evaluates their total contingent payoff based on the realized one-stage reward in an asynchronous manner
Players independently update their policies by incorporating a smoothed optimal one-stage deviation strategy based on the estimated Q-function
Q-function estimates are updated at a faster rate than policies
Policies induced by these learning dynamics converge to a stationary Nash equilibrium in Markov Potential Games with probability 1
Summary : Agents can reach a stationary Nash equilibrium in Markov potential games through simple learning dynamics under the minimum information environment.
Sections
Introduction
Related Works
Game Model
Independent and Decentralized Learning Dynamics
Numerical Experiments
Conclusions
Introduction
MARL - Multi-Agent Reinforcement Learning
Studies the interactions among multiple players in a dynamic environment, where the utilities and state transition are jointly determined by the players actions
Autonomous driving, adaptative traffic control, e-commerce, real-time strategy games
Markov Potential Game
A game is said to be a potential game if the incentive of all players to change their strategy can be expressed through a single gobal function called the potential function
Mixed competitive and cooperative scenario
Markov games which satisfy the conditions for MPG's:
Identical interest games - cooperation
Stochastic Congestion Games - competition through congestion
The change of utility of any player from unilaterally deviating their policy can be evaluated by the change on the potential function
A stationary Nash equilibrium can be solved as the global optimum of the potential function
Gradient-based algorithms
Used to compute the stationary Nash Equilibrium
Gradient calculation require agents to compute the value function or its derivatives for the policy update which necesitates access to simulator/oracle or coordination/communication between players
How can naive players learn a stationary Nash Equilibrium through simple updates without coordination and without knowledge of the game?
This papers answers by proposing and independent and decentralized multi-agent reinforcement learning dynamics
Proves its convergence to stationary Nash equilibrium in infinite-horizon discounted Markov Potential Games.
Minimal Information Environment
Each player only observes the realized state and their own realized reward
Players do not know the existence of other players, nor their own or foes' utility functions or the state transition probability function
Learning Dynamics
Players individually deploying a decentralized two-scale q-learning dynamics
Players mantain a q-estimate for each value-action pair
Players update their policies based on the updated q-estimate
Players are self-interested
Learning is asynchronous and heterogeneous among players
Only the q-estimate of the realized state-action pair is updated
Only the policy regarding the realized state is updated
Each player counts the number of times a state and action is realized and adjusts the stepsize for updating hat state and action element according to the counter
The dynamics have two timescales: the q-estimate is updated at a faster rate than the policy update
Proof
These learning dinamics lead to an approximate Nash equilibrium with probability 1, which becomes a Nash equilibrium when the payoff perturbation goes to zero
Conclusion
Nash equilibrium can be achieved in Markov potential games under the minimum information environment without coordination among players
The End
I hoped you liked this week’s post on Notes on Reinforcement Learning. Tune next week for more, probably with an addition of a summary of the article The Challenge of Value Alignment: from Fairer Algorithms to AI Safety