Notes on Reinforcement Learning 3: Fixing RL Research
Towards Deployable RL, Exploration in Deep Reinforcement Learning and Risk Sensitive Dead-end Identification in Safety-Critical Offline Reinforcement Learning

Good morning everyone, this week’s notes come packed with features. As promised in last week’s post, this will include a detailed summary of Towards Deployable RL - What’s Broken with RL Research and a Potential Fix, as well as the classification of announced papers on arxiv.org and an overview of my favourites. We’ll begin with this week’s favourites, continue with today’s feature, then the sorted articles on arxiv.org and finish with some notes.
Subscribe to receive next week’s review of Reinforcement Learning from Human Feedback, and why it is important for the deployment of chatGPT.
My favourites
Of those announced on arxiv (9th-16th January), these are the ones that captured my attention . I’m sure other researchers would have chosen differently but I thought these are of great quality.
Risk Sensitive Dead-end Identification in Safety-Critical Offline Reinforcement Learning
How to prevent worst-case scenarios or dead-ends in Reinforcement Learning (this ties with this chapter on last week’s feature, on how to ensure agents explore the world in a safe manner)
Learning to Perceive in Deep Model-Free Reinforcement Learning
Exploration in Deep Reinforcement Learning: From Single-Agent to Multi-Agent Domain
This is actually from 2021 but updated on 2023.
A survey on the state of the art in exploration, both for single to multiple agents.
Decentralized model-free reinforcement learning in stochastic games with average-reward objective
Score vs. Winrate in Score-Based Games: which Reward for Reinforcement Learning?
At the end of this newsletter I’ll include my notes on Risk Sensitive Dead-end Identification in Safety-Critical Offline Reinforcement Learning and Exploration in Deep Reinforcement Learning: From Single-Agent to Multi-Agent Domain.
Towards Deployable RL - What’s Broken with RL Research and a Potential Fix
This is a paper written by Shie Mannor and Aviv Tamar, both at Technion, Israel’s Institute of Technology. I would characterize this paper as a Deployable RL manifesto, as its aim is to encourage research practices that close the current gap between RL and real-world applications. To them, deployable AI means RL that can work at scale, be economically feasible, and can eventually be put in the field.
They heavily criticise current focus on benchmarks, arguing that it yields very little practical value, and instead advocate for a focus on challenges, which they define as a real-world problem sponsored by a group of researchers from academia/industry. In their words: instead of comparing algorithms, solve a real world problem and bring real-world value.
They end by encouraging people to contribute challenges, frame their own research with this point of view and criticise research that is void of real-world value.
Here I offer you a schematic, heavily summarized version, but I encourage you to also read the full thing at Aviv Tamar’s Substack, link at the end.
Sections
Introduction
Generalist Agents VS Deployable RL Systems
Principles of Deployable RL Research
Actionable Next Steps
1. Introduction
RL is not living up to our expectations.
Here are five popular research practices that were relevant for 2015, but are currently stagnating the field:
Overfitting to Specific Benchmarks
Nearly every paper is required to show some distinction for one of the popular benchmarks (Atari, Mujoco...) which leads to tweaks that only work for those benchmarks.
Progress in benchmarks does not yield tangible real-world value
Wrong Focus
Current benchmarks ignore the deployable nature of situated (RL-driven) agents completely, focusing on algorithms rather than on a system/engineering view.
OpenAI GYM abstracts away all system-design issues
This hampers progress since in many practical problems, figuring out what are the useful states, actions, and rewards is a critical component of the development process
Detached Theory
Useful theory seems to be quite rare:
Regret minimization is overly pessimistic
There is a lot of prior knowledge in practical problems that is not accounted for
Finite states and actions are not a good model for many problems of interest
There is a focus on unimportant qualities
Uneven Playing Grounds
Performance is confounded by resources available to the implementer:
Proficiency in hyper-parameter tuning
Size of NN
Prior knowledge about the problem/solution
Variability of scale and the current trend at top conferences to prefer masive experimentation over conceptual novelty, can inhibit long-term progress
Lack of Experimental rigor
Impressive singular experiments give a false sense of progress
We need more rigorous evaluation of difficulty and success: stability, deployment time and cost, testability and life-cycles are critical
The publication standard is that failure cases are almost never reported, stability is impossible to tell, and software design issues are not discussed.
2. Generalist Agents vs Deployable RL Systems
Two views:
Generalist/AI first: Future progress will be made by focusing attention on large-scale training of agents that solve diverse problems, with the hope that along the way a generalist agent will develop, and be a useful component in various real world problems
Deployable RL/RL second: Seek to design RL algorithms that solve concrete real world problems
The five problems from the introduction are relevant to both approaches but, with the current state of the field, we should seek the second (Deployed RL) approach.
3. Principles of Deployable RL Research
At present, RL is uneconomical to deploy.
To change it we need:
to research on how to deploy it effectively
to understand better the gains RL brings to practical problems
They propose a constructive model with three general principles around challenges:
Challenges instead of benchmarks:
Challenge: problem sponsored by a group of researchers from academia/industry: instead of comparing algorithms, solve a real world problem and bring real world value
Credit for contributing challenges: A rigorous presentation of a challenge (description, community and supporting platform) should be credited
Measurable progress is the main criterion for publication: Every publication should explain the limitations and issues with the proposed algorithm and how it addresses problems specifically.
Weight class: Computing power available should be reported to address the significance of the results
Theory papers shoud address specific challenges:
The goal of the research should be well justified in terms of its potential impact on real world problems. Should also consider problems that have to do with the life cycle of software such as data acquisition, debugging, testability and performance deterioration.
Design Patterns Oriented Research:
Real-world RL based systems should have conceptual solutions to problems where issues such as terstability, debuggability, and other system life-cycle issues are addressed.
We forsee that one way to make significant progress on a challenge would be by developing novel design patterns for it.
4. Actionable Next Steps:
To us, deployable RL means RL that can work at scale, be economically feasible, and can eventually be put in the field.
Here is what you can do:
Contribute challenges:
Requires deep understanding of the application domain, with many disciplines of impact (healthcare, engineering...)
Might require industry and academia joining forces
Frame your own research: Frame the research effort within deployable RL principles.
Critize others' research: Coordinate with researchers, reviewers and area chairs. Ask how a paper gets the field closer to real-world impact.
You can find find the whole article over at Aviv Tamar’s Substack or at arxiv.org.

Announced Papers: 9th-16th January
Engineering Applications
From Ember to Blaze: Swift Interactive Video Adaptation via Meta-Reinforcement Learning
Hierarchical Deep Q-Learning Based Handover in Wireless Networks with Dual Connectivity
Traffic Steering for 5G Multi-RAT Deployments using Deep Reinforcement Learning
Reinforcement Learning-based Joint Handover and Beam Tracking in Millimeter-wave Networks
MotorFactory: A Blender Add-on for Large Dataset Generation of Small Electric Motors
Long-distance migration with minimal energy consumption in a thermal turbulent environment
A Decentralized Pilot Assignment Methodology for Scalable O-RAN Cell-Free Massive MIMO
Efficient Preference-Based Reinforcement Learning Using Learned Dynamics Models
SoK: Adversarial Machine Learning Attacks and Defences in Multi-Agent Reinforcement Learning
Interesting
ORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
Deep Reinforcement Learning for Autonomous Ground Vehicle Exploration Without A-Priori Maps
Hint assisted reinforcement learning: an application in radio astronomy
Why People Skip Music? On Predicting Music Skips using Deep Reinforcement Learning
Imbalanced Classication In Faulty Turbine Data: New Proximal Policy Optimization
Learning-based Design and Control for Quadrupedal Robots with Parallel-Elastic Actuators
Multi-UAV Path Learning for Age and Power Optimization in IoT with UAV Battery Recharge
Tuning Path Tracking Controllers for Autonomous Cars Using Reinforcement Learning
Network Slicing via Transfer Learning aided Distributed Deep Reinforcement Learning
Enabling AI-Generated Content (AIGC) Services in Wireless Edge Networks
Locomotion-Action-Manipulation: Synthesizing Human-Scene Interactions in Complex 3D Environments
Fairness Guaranteed and Auction-based x-haul and Cloud Resource Allocation in Multi-tenant O-RANs
RL-DWA Omnidirectional Motion Planning for Person Following in Domestic Assistance and Monitoring
ECSAS: Exploring Critical Scenarios from Action Sequence in Autonomous Driving
TarGF: Learning Target Gradient Field for Object Rearrangement
MoCapAct: A Multi-Task Dataset for Simulated Humanoid Control
When to Trust Your Simulator: Dynamics-Aware Hybrid Offline-and-Online Reinforcement Learning
DROPO: Sim-to-Real Transfer with Offline Domain Randomization
Healthcare Applications
Mathematical Theory
Time-Myopic Go-Explore: Learning A State Representation for the Go-Explore Paradigm
Approximate Information States for Worst-Case Control and Learning in Uncertain Systems
Safe Policy Improvement for POMDPs via Finite-State Controllers
Sequential Fair Resource Allocation under a Markov Decision Process Framework
IMKGA-SM: Interpretable Multimodal Knowledge Graph Answer Prediction via Sequence Modeling
SkillS: Adaptive Skill Sequencing for Efficient Temporally-Extended Exploration
Max-Min Off-Policy Actor-Critic Method Focusing on Worst-Case Robustness to Model Misspecification
An approximate policy iteration viewpoint of actor-critic algorithms
A Deep Reinforcement Learning Framework for Column Generation
Investigating the Properties of Neural Network Representations in Reinforcement Learning
Trajectory Modeling via Random Utility Inverse Reinforcement Learning
Reinforcement Learning Theory
Risk Sensitive Dead-end Identification in Safety-Critical Offline Reinforcement Learning
Mutation Testing of Deep Reinforcement Learning Based on Real Faults
Predictive World Models from Real-World Partial Observations
schlably: A Python Framework for Deep Reinforcement Learning Based Scheduling Experiments
Actor-Director-Critic: A Novel Deep Reinforcement Learning Framework
Learning to Perceive in Deep Model-Free Reinforcement Learning
Robust Deep Reinforcement Learning through Bootstrapped Opportunistic Curriculum
Universally Expressive Communication in Multi-Agent Reinforcement Learning
When does return-conditioned supervised learning work for offline reinforcement learning?
A Generic Graph Sparsification Framework using Deep Reinforcement Learning
Exploration in Deep Reinforcement Learning: From Single-Agent to Multi-Agent Domain
Pessimistic Model-based Offline Reinforcement Learning under Partial Coverage
Reinforcement Learning for Joint Optimization of Multiple Rewards
Financial Applications
Transformer Theory
Game Theory
Decentralized model-free reinforcement learning in stochastic games with average-reward objective
On Reinforcement Learning for the Game of 2048- Phd dissertation
Score vs. Winrate in Score-Based Games: which Reward for Reinforcement Learning?
On the Complexity of Computing Markov Perfect Equilibrium in General-Sum Stochastic Games
Notes on Reinforcement Learning 3.1: Risk Sensitive Dead-end Identification in Safety-Critical Offline Reinforcement Learning
One of the problems highlighted in The Challenge of IA Value Alignment
GREAT PAPER
Taylor K William - University of Toronto
Sonali Parbhoo - Imperial College London
Marzyeh Ghassemi - Massachussets Institute of Technology
Abstract
Identifying worst-case scenarios or dead-ends is crucial in safety-critical scenarios
This situations are rife with uncertainity due to stochastic environments and limited offline training data
Distributional Dead-End Discovery (DistDeD): a framework to identify worst-case decision points based on estimated distributions of the return of a decision.
Used on a toy domain as well as assesing the risk of death severely ill patients
Results: improves prior discovery approaches by increasing detection 20% and providing indications of the risk 10 hours earlier on average
Sections
Introduction
Related Work
Safe and Risk-Sensitive RL
Non-stationary and Uncertainty-Aware RL
RL in safety critical domains
Preliminaries
Distributional RL
Conservatism in Offline RL
Risk Estimation
Dead-end Discovery (DeD)
Risk-sensitive Dead-end Discovery
Illustrative Demonstration of DistDeD
Assesing Medical Dead-ends with DistDeD
Data
State Construction
D- and R- Networks
Training
Experimental Setup
Results
DistDeD Provides earlier Warning of Patient Risk
DistDeD Allows for a Tunable Assesment of Risk
CQL Enhances DistDeD Performance
Discussion
Limitations
Broader Impact
Author Contributions
Acknowledgements
1. Introduction
In complex, safety-critical scenarios, being able to identify signs of rapid deterioration is critical: like replacing components within high value machinery or healthcare evaluation
Quantifying worst--case outcomes is usually challenging as a result of unknown stochasticity in the environment (compunded over a sequence of decisions), potentially changing dynamics, and limited data.
RL is a natural paradigm to address sequential decision-making tasks in safety-critical settings, focusing on maximizing the cumulative effects of decisions over time.
Many approaches relie on a priori knowledge about which states and actions to avoid, but this is not feasible in many real-world tasks as this may be unknown due to unknown interactions between selected actions and the observed state.
RL in high-risk settings is fully offline and off-policy due to ethical and legal reasons. As a consequence, it is very affected by the data collected and confounding information may lead to the overestimation of anticipated return, biased decisions and/or overconfident yet erroneous predictions, as well as overlooking rare but dangerous situations.
In general, Rl has been used in risk-neutral situations.
DeD (cite) is a framework that takes into account risk by avoiding actions proportionally to their risk of leading to dead-ends.
Recorded negative outcomes are leveraged to identify behaviours that should be avoided
Actions that lead to dead-ends are identified based on threshold point-estimates of the expected return of an action rather than considering the full distribution
Risk estimation in DeD is limited and too optimistic about determining which actions should be avoided.
By underestimating the risk associated with a particular action, we are unable to determine whether an action could be potentially dangerous.
DistDeD:
Risk-sensitive decision framework positioned to serve as an early-warning system for dead-end discovery
Tool for thinking about risk-sensitivy in data-limited offline settings
Contributions:
Provide distributional estimates of the return to determine whether a certain state is at risk of becoming a dead-end from the expected worst-case outcomes over available decisions.
Establish DistDeD as a lower bound to DeD results -> Able to detect and provide earlier indication of high risk scenarios
Modelling the full distribution -> Spectrum of risk-sensitivity when assesing dead-ends, tunable risk estimation procedures and can be customized
Empirical evidence that DistDeD enables an earlier determination of high-risk areas of the state space on both a simulated environment and a real-world application.
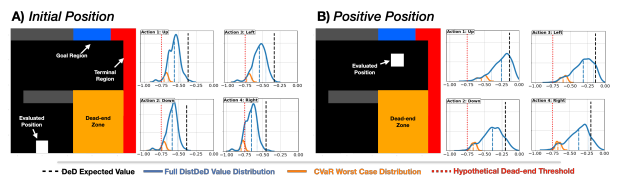
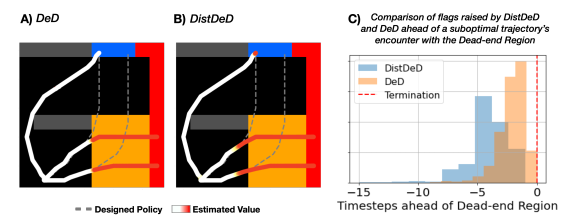
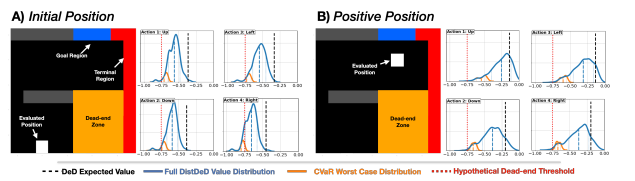
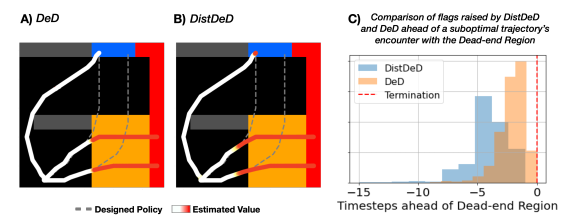
7. Discussion
Justification, foundational evidence and preliminary findings on DistDeD
Limitations:
Discrete action spaces
Binary reward signal
Dead-ends are derived from a single condition, most real world-scenarios are more complex
Does not make causal claims about the impact of each action
Broader Impact
Intended for assistance to domain experts, not for usage in isolation
It asseses high-risk situations early enough so that the human decision maker can make a decision
Misuse could be fatal
Notes on Reinforcement Learning 3.2: Exploration in Deep Reinforcement Learning: From Single-Agent to Multi-Agent Domain
2021 -IEEE Transactions on Neural Networks and Learning Systems
Updated 12 January 2023
Abstract
DRL and MARL is known to be sample inefficient, preventing real-world applications
One bottleneck is the exploration challenge: how to efficiently explore the environment collecting informative experiences
Comprehensive survey on existing exploration methods for both single-agent and multi-agent RL.
First: identify challenges
Second: Survey with two categories: uncertainity-oriented exploration and motivation-oriented exploration, as well as other notable exploration methods
Both algorithmic analysis and comparison on DRL benchmarks
Summarization and future directions
Sections
Introduction
Preliminaries
Markov Decision Process & Markov Game
Reinforcement Learning Methods
Value-based methods
Policy Gradient Methods
Actor-Critic Methods
MARL Algorithms
Basic Exploration Techniques
Epsilon-Greedy
Upper Confidence Bounds
Entropy Regularization
Noise Perturbation
Exploration based on Bayesian Optimization
Gaussian Process-Upper Confidence Bounds (GP-UCB)
Thompson Sampling (TS)
What Makes Exploration Hard in RL
Large State-action Space
Sparse, Delayed Rewards
White-noise Problem
Multi-agent Exploration
Exploration in Single-agent DRL
Uncertainity-oriented Exploration
Exploration under Epistemic uncertainty
Parametric Posterior-based Exploration
Non-parametric Posterior-based Exploration
Exploration under Aleatoric Uncertainty
Exploration under Both Types of Uncertainty
Intrinsic Motivation-oriented Exploration
Prediction Error
Novelty
Information Gain
Other Advanced Methods for Exploration
Distributed Exploration
Exploration with Parametric Noise
Safe Exploration
Exploration in Multi-Agent DRL
Uncertainty-oriented Exploration
Intrinsic Motivation-oriented Exploration
Other Methods for Multi-Agent Exploration
Discussion
Empirical Analysis
Open Problems
Exploration in Large Open space
Exploration in Long-horizon Environments with Extremely Sparse, Delayed Rewards
Exploration with White Noise Problem
Convergence
Multi-Agent Exploration
Safe Exploration
Conclusion
7. Conclusion
Suggestions and insights:
Current Exploration methods are evaluated mainly in terms of cumulative rewards and sample efficient on a handful of well-known environments
The essential connections beteen different exploration methods are to be further revealed
Exploration among large action space, long horizon environments and convergence analysis are relatively lacking studies
Multi-Agent Exploration can be even more challenging due to complex multi-agent interactions. Coordinated exploration with decentralized execution and exploration under non-stationarity may be the key problems to address.
The end
This has been this week’s post on Notes on Reinforcement Learning. Tune next week for a review of Reinforcement Learning from Human Feedback, and why it is important for the deployment of chatGPT.