Notes on Reinforcement Learning 19
Replicability crisis and Language Models

Good Morning Everyone!
One of the most important research topics in the RL community has been lately the study of how to make our research more scientific, applicable, and replicable.
On a more global scale, it is no secret that the scientific community has been suffering a replicability crisis, with lots of research being questioned because of the impossibility to repeat it with similar results. It has mostly been tackled in medicine and psychology, but ML researchers have the same concerns, as our research is heavily dependent on the amount of compute and resources, as well as random seeds and methodology.
The paper Towards Deployable RL - What’s Broken with RL Research and a Potential Fix highlights the problem (NRL 3), Empirical Design in Reinforcement Learning tackles it through an educational perspective on good practices (Currently in chapter 4, we will have that summary!!), and this week’s publication, Replicable Reinforcement Learning tries to fix it by proposing an easily replicable algorithm.
In other news, LLM’s clearly are in vogue, and this week’s classification of articles reflects that, with more than 15 articles addressing the topic. At the end of this newsletter some very raw notes on last week’s highlighted article SneakyPrompt: Evaluating Robustness of Text-to-image Generative Models' Safety Filters.
On this week’s articles on LLM’s I found these two very interesting:
Mindstorms in Natural Language-Based Societies of Mind
Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks that engage in "Mindstorm" interviews to solve problems.
Recent implementations of these societies of minds involve large language models (LLMs) and other neural network-based experts communicating through a natural language interface, overcoming the limitations of single LLMs and improving multimodal zero-shot reasoning.
Natural language-based societies of mind (NLSOMs) allow for the easy addition of new agents using a universal symbolic language, facilitating modular expansion.
NLSOMs, with up to 129 members, have been assembled and experimented with, successfully addressing practical AI tasks such as visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving.
This serves as a foundation for future NLSOMs with billions of agents, potentially including humans, raising crucial research questions about social structures, the (dis)advantages of different governance models, and the application of neural network economies to maximize rewards in reinforcement learning NLSOMs.
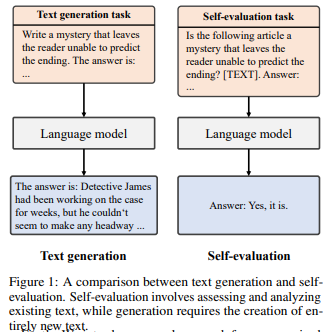
Language Model Self-improvement by Reinforcement Learning Contemplation
Large Language Models (LLMs) have shown impressive performance in NLP tasks, but fine-tuning them requires significant supervision, which is costly and time-consuming.
A new unsupervised method called Language Model Self-Improvement by Reinforcement Learning Contemplation (SIRLC) is introduced to enhance LLMs without external labels.
SIRLC leverages the LLM's ability to assess text quality and assigns it dual roles as a student and teacher. The LLM generates text and evaluates it, with reinforcement learning used to update the model parameters.
SIRLC demonstrates its effectiveness across various NLP tasks, including reasoning, text generation, and machine translation. Experimental results show improved performance without the need for external supervision, with increased answering accuracy for reasoning tasks and higher BERTScore for translation tasks. SIRLC is also applicable to models of different sizes.
Classification of articles (22nd-28th May)
Engineering Applications
Energy
Image & Video
Industrial Applications
Navigation
Networks
Distributed Online Rollout for Multivehicle Routing in Unmapped Environments
Scaling Serverless Functions in Edge Networks: A Reinforcement Learning Approach
Semantic-aware Transmission Scheduling: a Monotonicity-driven Deep Reinforcement Learning Approach
XRoute Environment: A Novel Reinforcement Learning Environment for Routingç
Robotics
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
Communication-Efficient Reinforcement Learning in Swarm Robotic Networks for Maze Exploration
Constrained Reinforcement Learning for Dynamic Material Handling
FurnitureBench: Reproducible Real-World Benchmark for Long-Horizon Complex Manipulation
M-EMBER: Tackling Long-Horizon Mobile Manipulation via Factorized Domain Transfer
Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
Reinforcement Learning Theory
Actor Critic
Attacks
Control Theory
Curriculum RL
Diffussion Models
Deep Reinforcement Learning
Distributed RL
Empirical Study of RL
Evolutionary Learning
Exploration Methods
Explainable/Interpretable Machine Learning
Feature Engineering
Generalization
Imitation / Inverse / Demonstration Reinforcement Learning
Markov Decision Processes / Deep Theory
Multi-Agent RL
Neural Networks
Offline RL
Online RL
Optimization
Policy/Value Optimization
Reinforcement Learning from Human Preferences/Feedback
Reward Optimization
Risk-sensitive/safe/constrained RL
Sample-efficiency
Teacher-Student Framework
Text-to-image
Theory of Information
Transfer RL
Transformers
Recommender Systems
Financial Applications
Human-agent interaction
Games and Game Theory
Byzantine Robust Cooperative Multi-Agent Reinforcement Learning as a Bayesian Game
Deterministic Algorithmic Approaches to Solve Generalised Wordle
Know your Enemy: Investigating Monte-Carlo Tree Search with Opponent Models in Pommerman
Lucy-SKG: Learning to Play Rocket League Efficiently Using Deep Reinforcement Learning
Reinforcement Learning With Reward Machines in Stochastic Games
Physics
Chemistry
Healthcare Applications
Natural Language Processing
Chain-of-Thought Hub: A Continuous Effort to Measure Large Language Models' Reasoning Performance
ChatGPT: A Study on its Utility for Ubiquitous Software Engineering Tasks
Gender Biases in Automatic Evaluation Metrics: A Case Study on Image Captioning
Harnessing the Power of Large Language Models for Natural Language to First-Order Logic Translation
Improving Language Models with Advantage-based Offline Policy Gradients
Inference-Time Policy Adapters (IPA): Tailoring Extreme-Scale LMs without Fine-tuning
Language Model Self-improvement by Reinforcement Learning Contemplation
Modeling Adversarial Attack on Pre-trained Language Models as Sequential Decision Making
On the Correspondence between Compositionality and Imitation in Emergent Neural Communication
Query Rewriting for Retrieval-Augmented Large Language Models
SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning
Mathematics
SneakyPrompt: Evaluating Robustness of Text-to-image Generative Models' Safety Filters
Abstract
One challenging problem of text-to-image generative models is the generation of Not-Safe-For-Work (NSFW) content
SneakyPrompt
First adversarial attack framework to evaluate the robustness of real-world safety filters in state-of-the-art generative models.
Searches for alternate tokens in a prompt that generates NSFW images so that the generated prompt (advesarial prompt) bypasses existing safety filters
Uses RL to guide an agent with positive rewardson semantic similarity and bypass success.
Evaluation
SneakyPrompt successfully generatess NSFW content on default closed-box safety filter DALL-E 2
Bypasses also several state-of-the-art safety filters on a StableDifussion model
Succesfully generates NSFW content and outperforms existing adversarial attacks
Sections
Introduction
Related Work and Preliminary
Problem Formulation
Definitions
Threat Model
Methodology
Overview
Baseline Search with Heuristics
Guided Search via Reinforcement Learning
Experimental Setup
Evaluation
RQ1: Effectiveness in bypassing safety filters
RQ2: Performance compared to baselines
RQ3: Study of different parameter selection
RQ4: Explanation of bypassing
Possible Defenses
Defense Type I: Input Filtering
Defense Type II: Training Improvement
Conclusion
1. Introduction
Text-to-image models may generate NSFW content
They adopt safety filters, that are bypassable because of their complexity
There is a need for a through study of the robustness of these filters
Attempts:
Treat them as a closed box and launcha a text-based adversarial attack
TextBugger, Textfooler, BAE
TextBugger
Generates utility-preserving adversarial texts against text classfication algorithms
A text-based attack focuses only on the bypass but not the quality of the generated images, because they are not designed for text-to-image models
Eg. When a text found bypasses the safety filter, the NSFW semantics may be lost as well
More over: may need large and numerous queries, very costly
Rando et al.
Reverse engineer StableDiffussion safety filter
Propose a manual strategy to bypass the safety filter with extra unrelated content to surround a target prompt
24% success rate
Sneaky Prompt
First automated framework
First adversarial prompt attack to evaluate safety filters on text-to-image models using different search strategies with RL and baselines such as beam, greedy and brute-force.
Available on the repository
Successfully finds adversarial prompts for SOTA models, including DALL-E and StableDiffusion
Outperforms existing adversarial models
8. Conclusion
First automated framework to evaluate the robustness of existing safety filters via searching the prompt space to find adversarial prompts that bypass safety filter but preserve the semantics
Categorize safety filters into three categories:
Text-based
Image-based
image-text-based
Evaluation
All existing safety filters are vulnerable to SneakyPrompt
Dall-E closed box safety filter is also vulnerable to SneakyPrompt, as opposed to all other existing attacks
SneakyPrompt outperforms all other algorithms in terms of bypass rate, FID score and number of queries
Defenses
Proposes possible defenses such as:
Input filtering
Training improvement
Expects text-to-image mantainers to improve their safety filters based on the findings of SneakyPrompt
This is all! Have a great week, see you next Monday.